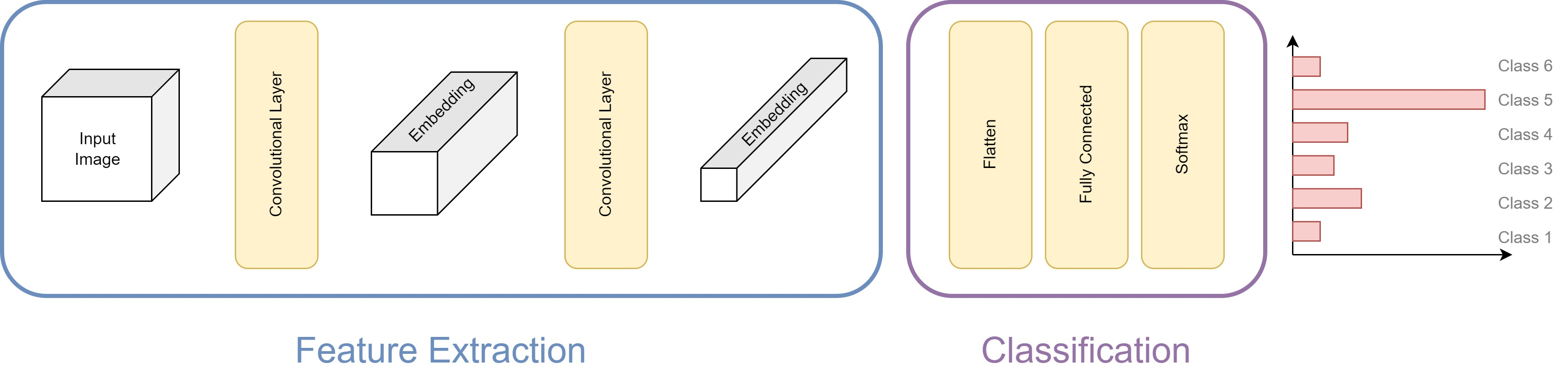
# Convolutional Neural Networks
A convolutional neural network (CNN) is a type of deep learning network that is particularly effective for processing grid-like data, such as images or sequences. CNNs are designed to automatically learn hierarchical representations of patterns and features directly from the input data.
In a CNN, the convolutional layers are responsible for extracting local patterns and features from the input. These layers consist of multiple filters or kernels that slide over the input data, performing convolution operations to produce feature maps. Convolutional layers are effective in capturing spatial relationships and detecting local patterns, such as edges or textures.
### Prediction Heads
Now, let's discuss the components of the prediction head in a CNN:
#### Flatten Layer
The flatten layer is used to convert the multi-dimensional feature maps from the convolutional layers into a single vector. It reshapes the output from the convolutional layers into a flat or one-dimensional tensor. This is necessary because the subsequent layers in the prediction head, such as fully connected or linear layers, expect a one-dimensional input. The flatten layer essentially "flattens" the spatial information into a feature vector, while preserving the learned representations.
#### Linear Layer
The linear layer, also known as a fully connected layer or dense layer, is a type of neural network layer where each neuron is connected to every neuron in the previous layer. The linear layer performs a linear transformation on the input data by applying a matrix multiplication followed by a bias term. It learns to map the input features to a higher-dimensional space, enabling the network to capture complex relationships between the features. The linear layer can be thought of as a feature extractor that maps the flattened input to an intermediate representation.
#### Softmax Layer
The softmax layer is typically the final layer in the prediction head of a classification CNN. It applies the softmax function to the outputs of the previous linear layer. The softmax function normalizes the output values, transforming them into a probability distribution over the different classes in a multi-class classification problem. The output values represent the predicted probabilities for each class, and they sum up to 1. The class with the highest probability is typically considered as the predicted class by the model.
In summary, the flatten layer is used to reshape the output from the convolutional layers into a one-dimensional vector. The linear layer performs a linear transformation on the flattened features, mapping them to an intermediate representation. Finally, the softmax layer applies the softmax function to produce class probabilities for multi-class classification.
These components collectively form the prediction head of a CNN, which takes the learned representations from the convolutional layers and transforms them into predictions for a specific task, such as image classification.
### Which CNNs do exist?
The honest answer to the question "How many CNN architectures exist" would be "possible more than one million". Everyone can implement his or her own CNN architecture. But there are a few number of models that have proofen to work good in real life use cases. I will give you a short introduction to three of these models:
#### ***VGG***
VGG is a classical convolutional neural network that was introduced in 2015 in the paper [Very Deep Convolutional Networks for large-scale Image recognition](https://arxiv.org/pdf/1409.1556.pdf) and outperformed previous existing architectures. The VGG model comes in different sizes starting with the smallest variant named VGG11 and ending with the largest model named VGG19. Its benefits are that its architecture is easy to understand as it only consists of layers that we have discussed in this course. But its downsides are that the model has a lot of parameters which makes training harder. The largest variant VGG19 nearly uses 500MB disk space on a device.
Paper: [Very Deep Convolutional Networks for large-scale Image recognition](https://arxiv.org/pdf/1409.1556.pdf)
PyTorch: [VGG Models](https://pytorch.org/vision/stable/models/vgg.html)
***MobileNet***
The idea of MobileNet was to develop a small model that reaches high accuracies in image classification tasks. The advantages of MobilNet are that it is very small (10MB - 20MB) but still reaches good results in image classification tasks. It is so small that you even could train it on a CPU with a small image dataset. MobileNet was improved during the last years, so the current version of MobileNet is version 3. Also mobilnet comes in four different sizes. Check them out on PyTorch.
Paper: [Searching for mobileNet V3](https://arxiv.org/pdf/1905.02244.pdf)
PyTorch: [MobileNet V3 Models](https://pytorch.org/vision/main/models/mobilenetv3.html)
***ResNet***
ResNet is one of the most popular models in the computer vision domain. It was introduced in 2015 by microsoft and drives multiple famous model architectures for classification, object decetion and image segmentation. ResNet also comes in different sizes starting with ResNet18, continuing with ResNet34, Resnet50, ResNet101, and ending with ResNet 152. Especially ResNet50 is also used for other tasks than image classification such as object detection in the [Faster-RCNN](https://pytorch.org/vision/main/models/faster_rcnn.html) model, for image segmenation in the [Mask-R-CNN](https://pytorch.org/vision/main/models/mask_rcnn.html) model or for keypoint detection in the [Keypoint-R-CNN](https://pytorch.org/vision/main/models/keypoint_rcnn.html) model
Paper: [Deep Residual Learning for Image Recognition](https://arxiv.org/pdf/1512.03385.pdf)
PyTorch: [ResNet](https://pytorch.org/vision/main/models/resnet.html)
### More PyTorch Vision Models
You can get an overview of the (pretrained) computer vision models available in PyTorch here:
* [Image Classification](https://pytorch.org/vision/main/models.html#classification)
* [Object Detection](https://pytorch.org/vision/main/models.html#object-detection)
* [Keypoint Detection](https://pytorch.org/vision/main/models.html#keypoint-detection)
* [Instance Segmentation](https://pytorch.org/vision/main/models.html#instance-segmentation)
* [Semantic Segmentation](https://pytorch.org/vision/main/models.html#semantic-segmentation)
* [Video Classification](https://pytorch.org/vision/main/models.html#video-classification)
### Papers:
If you are interested into diving deeper into convolution in neural networks I highly recommend this paper: